"TW-CRL:Time-Weighted Contrastive Reward Learning for Efficient Inverse Reinforcement Learning" Accepted to AAAI 2026 (Oral)

Our work, “TW-CRL:Time-Weighted Contrastive Reward Learning for Efficient Inverse Reinforcement Learning”, was accepted and presented at AAAI 2026 for an oral presentation. This work was a collaboration between Yuxuan Li, Yicheng Gao, Ning Yang, and Stephen Xia.
Reinforcement learning systems are powerful, but they often struggle in the real world for a simple reason: failure is silent. In many tasks—robot navigation, manipulation, or control—agents receive a reward only when they succeed, and nothing at all when they make irreversible mistakes. These hidden “trap states” can doom an agent to fail repeatedly without ever being told what went wrong.
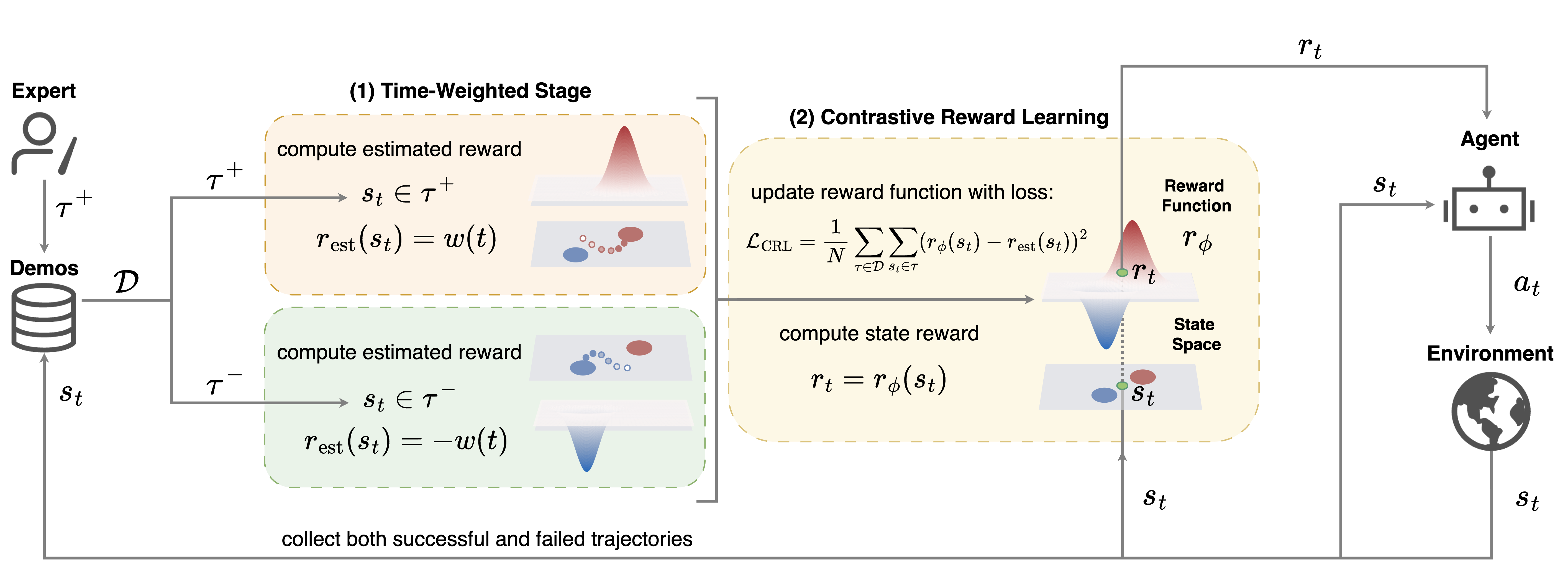
We present a new framework called Time-Weighted Contrastive Reward Learning (TW-CRL), which tackles this problem head-on by teaching agents to learn not just from success, but from failure, and to understand when those failures matter most.
What sets this work apart is its contrastive use of both successful and failed demonstrations. Rather than blindly imitating experts, the agent learns to distinguish states that move it closer to a goal from those that quietly push it toward failure. This allows the system to avoid unseen trap states, explore more intelligently, and go beyond simple imitation.
Moreover, instead of treating all steps in a demonstration equally, the method assigns greater importance to states that occur later in a trajectory, when success or failure becomes inevitable. By doing so, TW-CRL learns a dense, informative reward function that highlights critical decision points and implicitly penalizes states that lead to dead ends.
Across eight challenging benchmarks, from maze navigation with hidden traps to continuous-control robotics tasks, TW-CRL consistently outperforms state-of-the-art inverse reinforcement learning methods. It converges faster, achieves higher returns, and exhibits greater robustness, especially in environments where failure is common early on.
By formalizing the notion of trap states and showing how temporal structure and failed experiences can be turned into actionable learning signals, this work pushes reinforcement learning a step closer to real-world reliability, where knowing what not to do is just as important as knowing what works.
Congratulations to the team!