"MAESTRO: Adaptive Sparse Attention and Robust Learning for Multimodal Dynamic Time Series" Accepted and Presented at NeurIPS 2025 (Spotlight)
Our work, “MAESTRO: Adaptive Sparse Attention and Robust Learning for Multimodal Dynamic Time Series”, was accepted and presented at NeurIPS 2025 as a spotlight. This work was a collaboration between Payal Mohapatra, Yueyuan Sui, Akash Pandey, Stephen Xia, and Qi Zhu from Northwestern University.
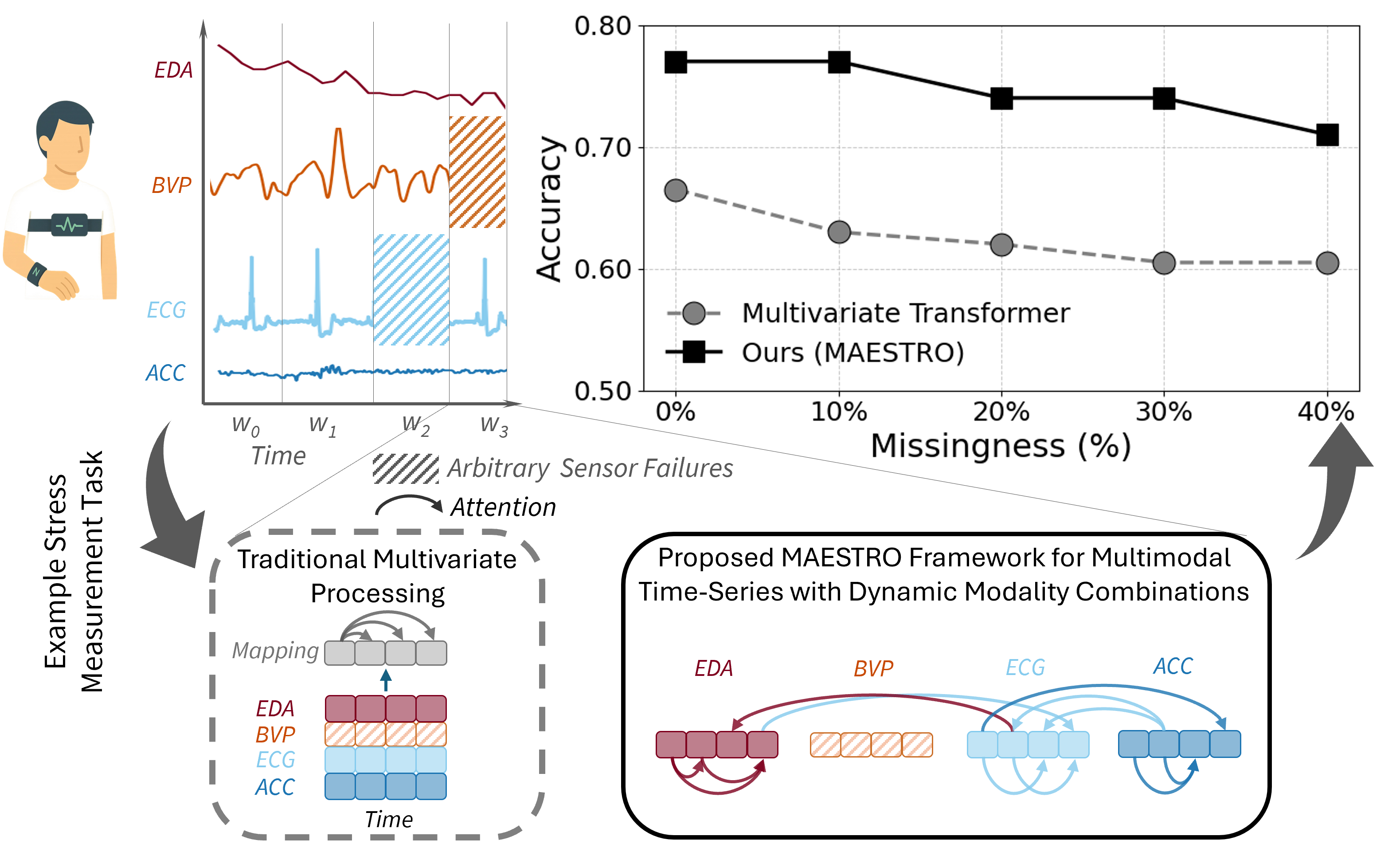
In this work, we present a new AI framework designed to make sense of dynamic, multimodal time-series data—even when large chunks of it are missing. Instead of forcing all sensor data into a rigid, one-size-fits-all model, MAESTRO adapts on the fly, deciding which signals matter most and how they should interact for a given task. Novelties, features, and contributions include:
(1) No “primary sensor: bias: Most existing systems depend on a single anchor modality (like video or motion). MAESTRO drops that assumption entirely, letting any modality take the lead when it’s most informative, and stepping back when it’s not.
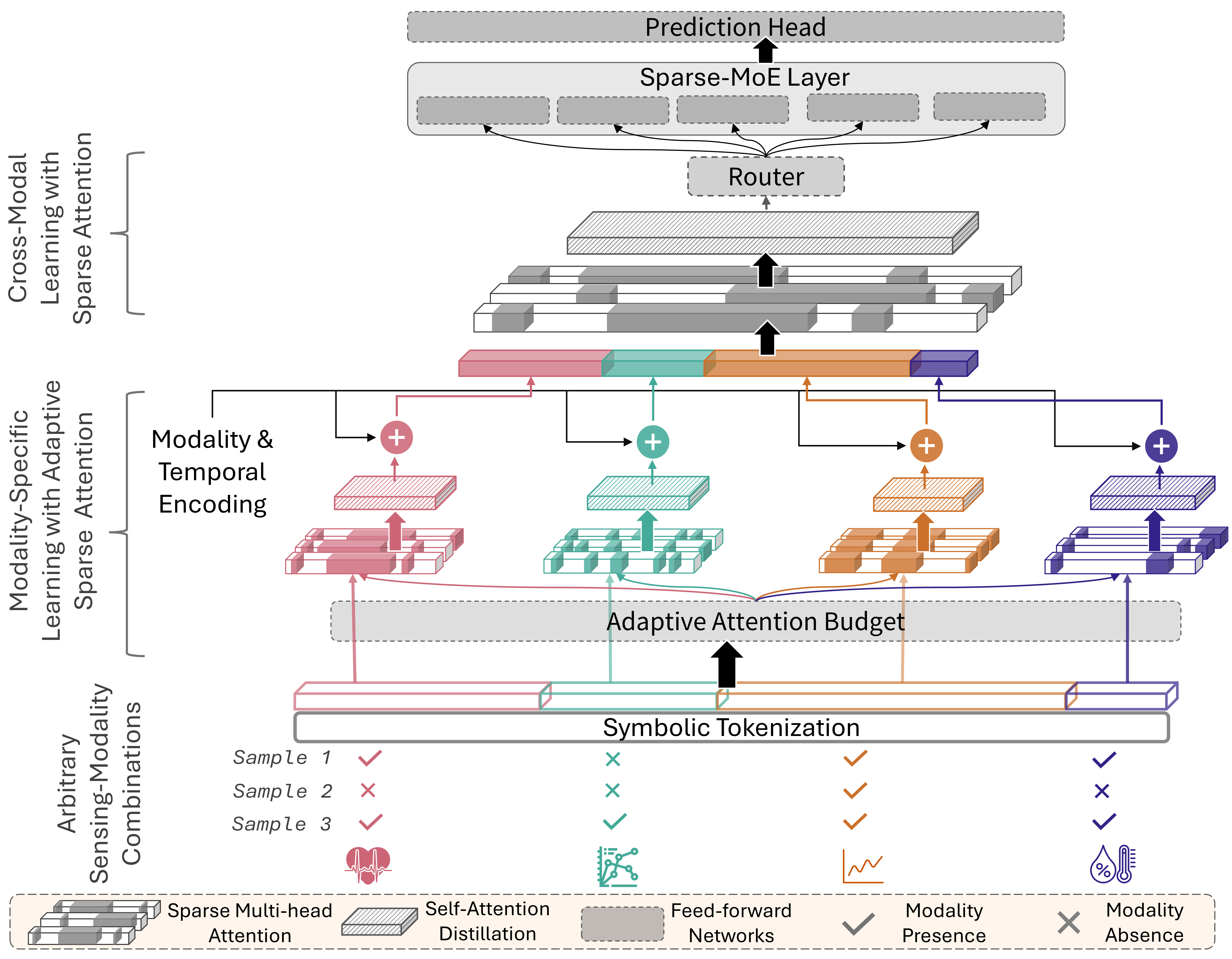
(2) Built for missing and failing sensors: Real deployments rarely have perfect data. MAESTRO explicitly encodes missing sensors using symbolic tokens and dynamically reallocates its attention budget, allowing it to remain accurate even when up to 40% of modalities are missing.
(3) Efficient learning at scale: Instead of expensive pairwise modeling between every sensor, MAESTRO builds a long multimodal sequence and processes it with sparse attention, reducing computation while still capturing rich cross-modal interactions.
(4) Adaptive expertise via Mixture-of-Experts: At the final stage, MAESTRO routes information through a sparse Mixture-of-Experts (MoE) layer. Different experts naturally specialize for different sensor combinations—without extra losses or hand-crafted rules—making the system robust and flexible in unpredictable settings.
We evaluate across four real-world datasets spanning healthcare, activity recognition, and clinical prediction—with as many as 17 sensing modalities. MAESTRO consistently outperforms strong multivariate and multimodal baselines, including 4–8% gains under full sensor availability, and ~9% average improvement when sensors are partially missing.
MAESTRO moves multimodal learning closer to real-world readiness, offering a general-purpose blueprint for learning from heterogeneous, unreliable sensor data. This is exactly the type of scenarios we see in wearables, mobile health, and IoT systems today.
If multimodal time-series learning is an orchestra, MAESTRO is the conductor that keeps the music playing—even when half the instruments drop out.
Congratulations to the team!