Audio Wearables for Urban Safety
Death and injury caused by accidents in urban areas have seen a sharp increase in recent years, especially from vehicle accidents. Our work in this sphere seeks to explore and develop novel technologies that can help reduce the number of accidents in urban areas and improve the overall safety of the general population. We explored two primary scenarios: pedestrian and construction worker safety.
PAWS: Improving Pedestrian Safety

With the prevalence of smartphones, pedestrians and joggers today often walk or run while listening to music. Since they are deprived of their auditory senses that would have provided important cues to dangers, they are at a much greater risk of being hit by cars or other vehicles. PAWS/SEUS is a wearable system that uses multi-channel audio sensors embedded in a headset to help detect and locate cars from their honks, engine and tire noises, and warn pedestrians of imminent dangers of approaching cars. The system acts as a second pair of ears in situations where the user’s sense of hearing is greatly diminished, such as when the user is taking a phone call or listening to music, and warns users of imminent dangers well in advance, allowing users ample time to react and avoid traffic accidents.
System Implementation
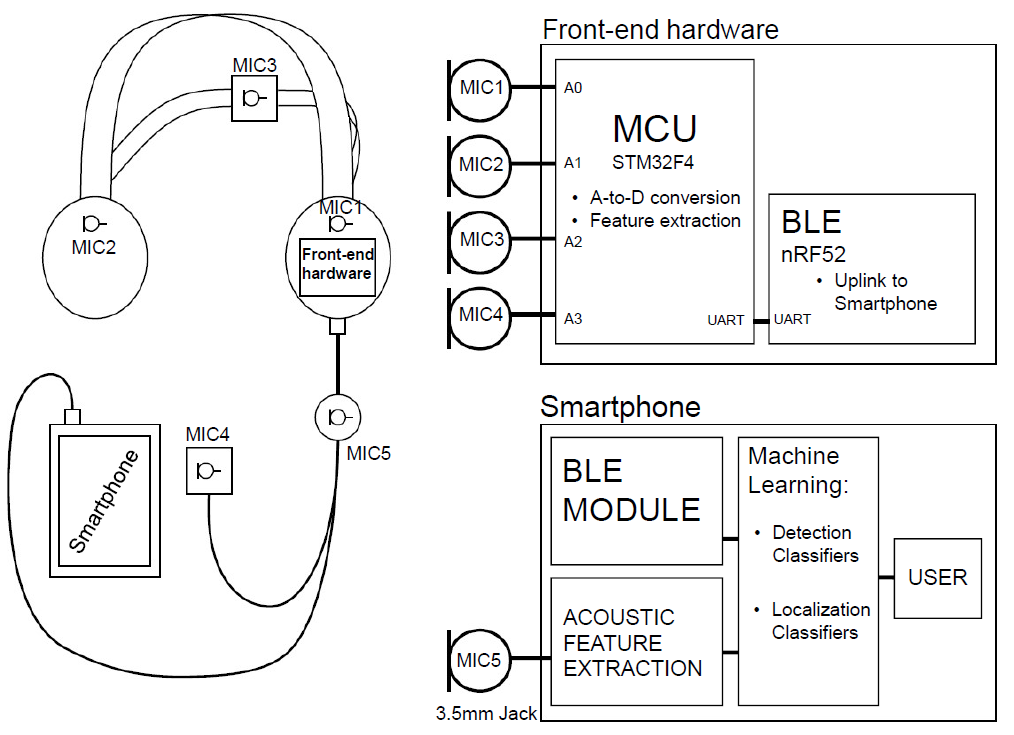
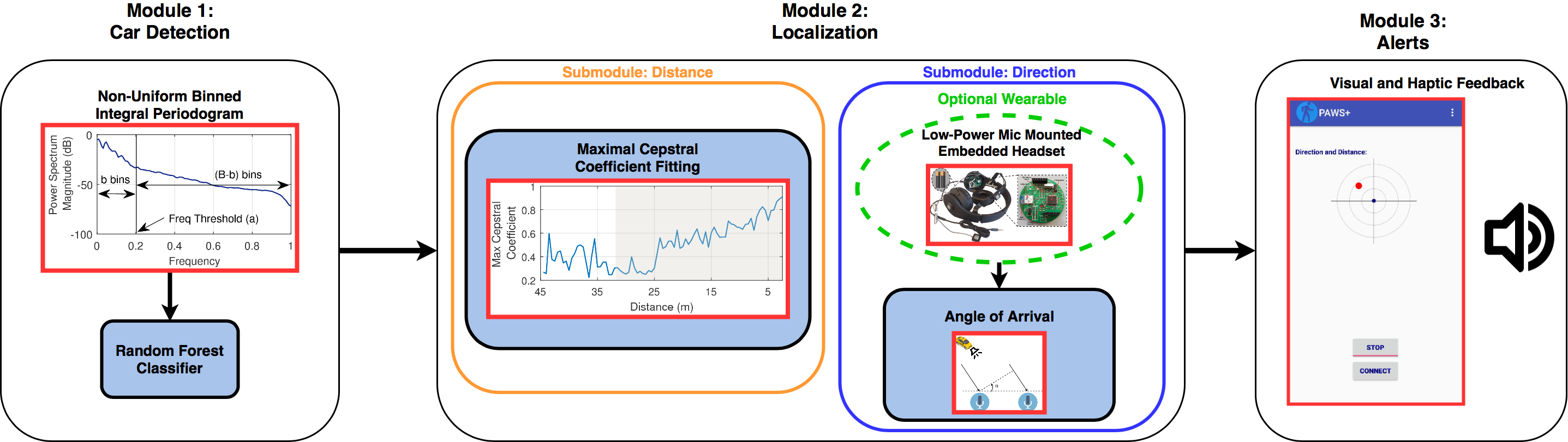
We develop a three stage architecture consisting of an array of headset mounted audio sensors, an embedded front end that samples from the audio sensors and performs signal processing and feature extraction on the observed audio signals, and a smartphone application that performs machine learning based classification using the features extracted from the embedded front end to detect and localize oncoming vehicles.
The audio sensors mounted on the headset are sampled by the embedded front-end platform, also housed within the headset, to estimate the interaural time difference (ITD) and interaural level difference (ILD) between the microphones. Just like in human ears, we leverage the differences between the time in which sounds arrive at each microphone (ITD) and the differences in the loudness of the sounds at each microphone (ILD) to estimate the direction of the car with respect to the user. The ITD and ILD features extracted from the embedded front-end are transmitted to the smartphone application, where we employ novel machine learning classifiers to detect and localize vehicles. A diagram of the headset integrated with the audio sensors and embedded front-end is shown below.

To detect vehicles, we propose a new frequency domain feature, Non-Uniform Binned Integral Periodogram (NBIP), that outperforms standard Mel-frequency cepstral coefficients (MFCCs) when used in a machine learning classifier to detect vehicles. Unlike standard MFCCs, NBIP allows designers to emphasize or de-emphasize different parts of the spectrum depending on the application at hand. We tuned the parameters for computing NBIP features that capture the most important portions of the spectrum for detecting vehicles and show that we are able to achieve a greater separation between vehicle and non-vehicle sounds using NBIPs than using standard MFCCs.
We evaluate PAWS in three different urban environments (in a college town, near a highway, in a metropolitan area), showing that the system is able to provide early danger detection in real-time, from up to 80m distance, with up to 99% precision and 97% recall, and alert the user on time (about 6s in advance for a 30mph car).
Reducing Power Consumption

In order for the system to be practical, it needs to be long-lasting. To reduce the power consumption of the embedded front-end platform, we propose, implemented, and incorporated an application-specific integrated circuit (ASIC). The ASIC uses polarity coincidence correlation (PCC) to estimate the interaural time differences between microphones at nano-watt level power consumption. This reduced the power consumption of the embedded front-end platform by an order of magnitude, allowing the system to run continuously on two coin cell batteries for almost a full day.
CSafe: Improving Construction Worker Safety
Vehicle-related accidents are one of the largest sources of construction worker injury. To help reduce the number of accidents involving construction workers, we introduce CSAFE, a low power wearable platform that uses multi-channel audio to detect, localize, and provide alerts about oncoming vehicles to improve construction worker safety. One of the biggest challenges in realizing this audio-based system is that construction sites are filled with hammering, power tools, and other noisy work sounds that can easily overpower the sound of an approaching vehicle. To address this challenge, we develop a novel source filtering architecture, capable of running on embedded and mobile platforms, that adaptively filters out loud construction sounds from the environment and greatly improves the detection and localization of vehicles.
Adaptive Construction Noise Filtering Architecture
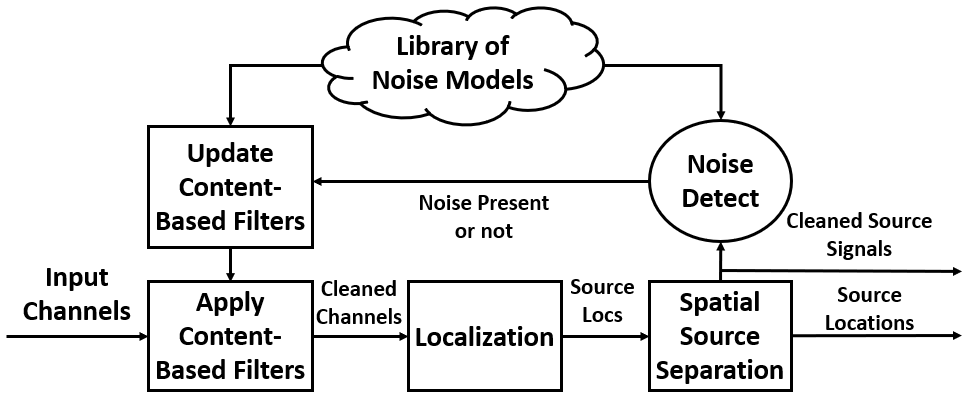
To account for loud construction tools that will be present in a construction site we propose an energy-efficient sound filtering architecture that contains content-based separation and spatial separation in a feedback configuration, which utilizes known or learned models of sounds to iteratively remove noise and boost target sounds. We introduce and integrate a novel content-based separation algorithm called Probabilistic Template Matching, that is capable of running in mobile devices and leverages statistical “templates” of noises to filter out construction sounds. Our novel filtering architecture differs from existing works in sound source separation in that we intelligently leverage both single-channel source separation and multi-channel source separation in a feedback architecture to more robustly remove overpowering construction noise over time.
Wearable Platform
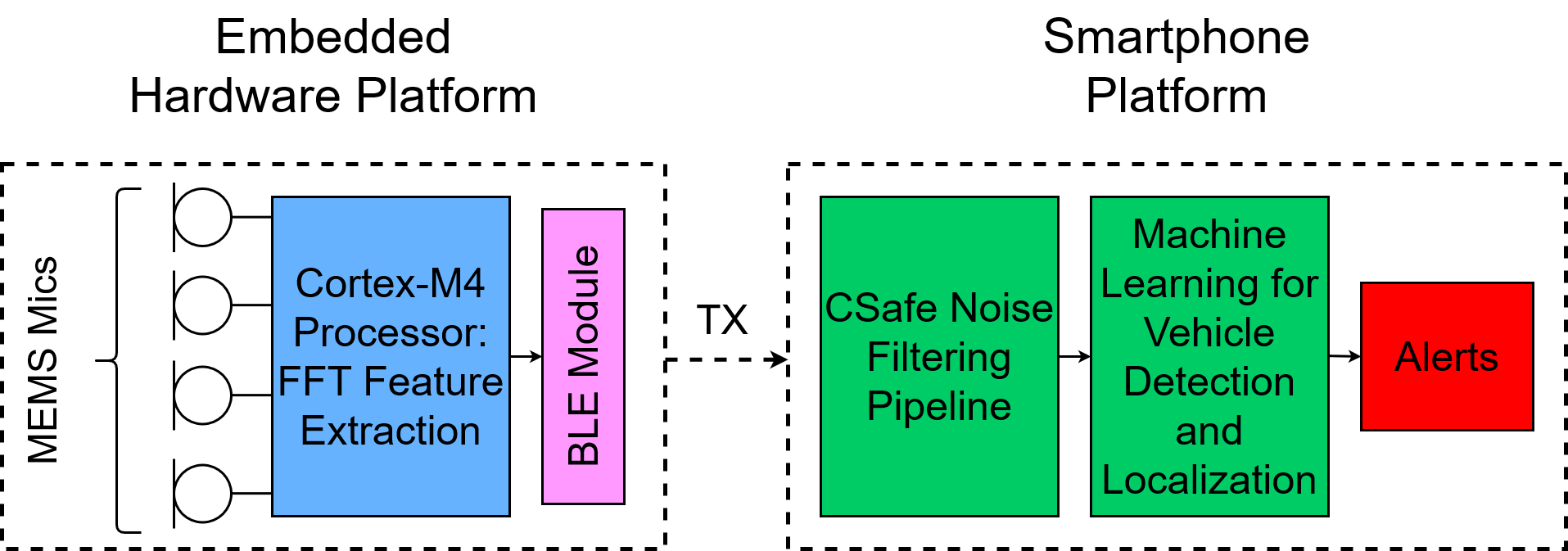
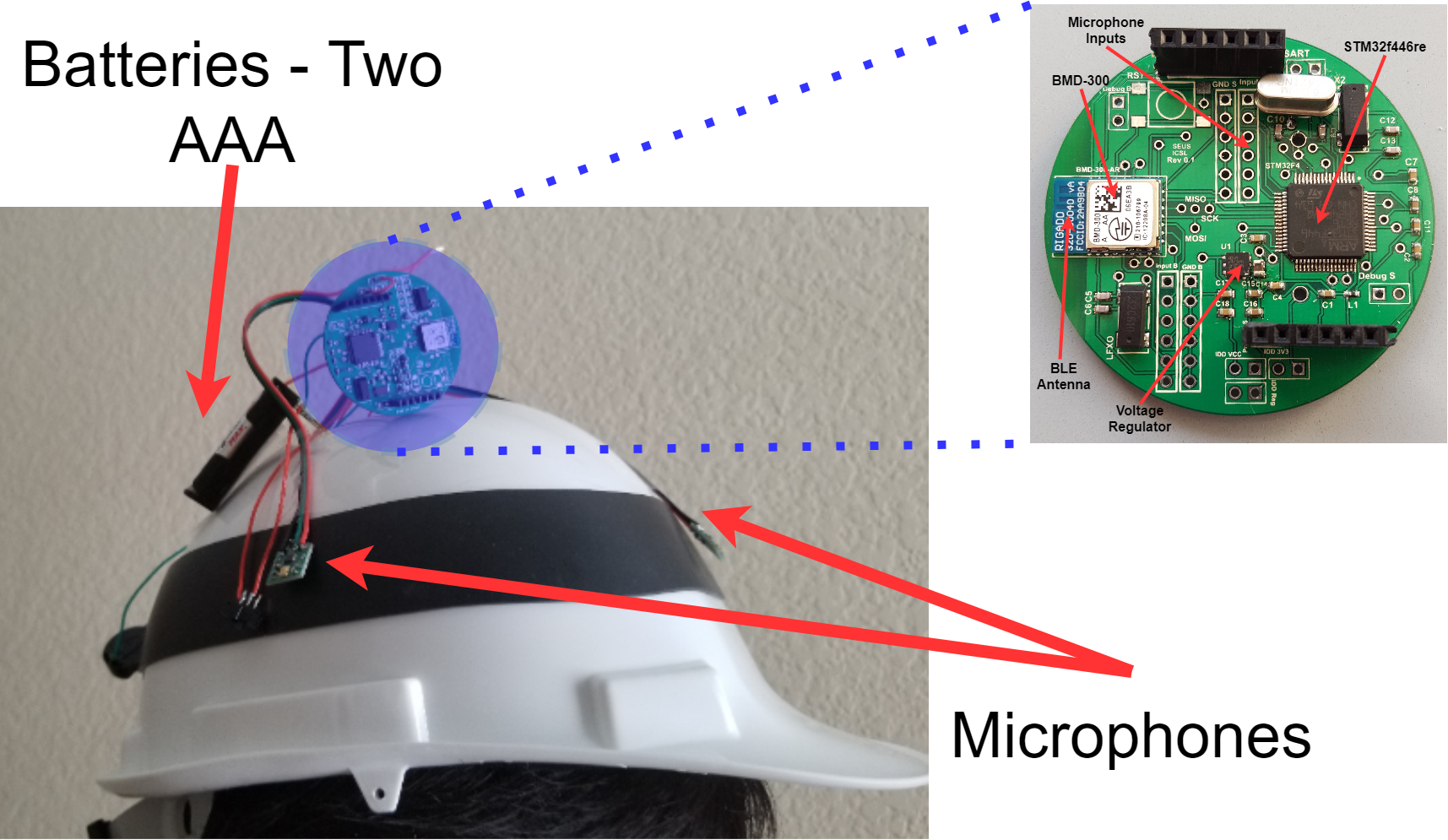
We incorporate our novel adaptive filtering pipeline into an embedded wearable platform consisting of an array of microphones mounted on a construction worker helmet. We leverage the embedded front-end hardware, developed in the PAWS project, to extract frequency domain features from each microphone and transmit them to the smartphone. The mobile device performs construction noise filtering using our novel adaptive filtering pipeline and runs machine learning algorithms on the filtered signals to perform vehicle detection and localization.
We evaluate CSAFE at a real construction site, with a wide variety of construction work noises, and show that CSAFE greatly improves vehicle detection and localization over existing works.
Code and Media
Publications
2021

2019
2018
2016
